1. Introduction
Natural disasters affect human and animal lives and properties all around the globe. In many cases the reasons are not in our control. As noted in [1], for the three decades namely 1970–80 (rank 2nd), 1980–90 (rank 4th), 1990–00 (rank 2nd), India ranks in first 5 countries in terms of absolute number of the loss of human life. It is not only the immediate effect as observed in [2], and exposure to a natural disaster in the past months increases the likelihood of acute illnesses such as diarrhea, fever, and acute respiratory illness in children under 5 year by 9–18%. The socioeconomic status of the households has a direct bearing on the magnitude and nature of these effects. The disasters have pronounced effects on business houses as well. As stated in [3] 40% of the companies, which were closed for consecutive 3 days, failed or closed down within a period of 36 months. The disasters are not infrequent as well. Only for earthquake [4], there are as many as 20 earthquakes every year which has a Richter scale reading greater than 7.0. The effects of the disasters are much more pronounced in developing countries like India.
Meteorologist, Geologists, Environmental Scientists, Computer Scientists and Scientists from various other disciplines have put a lot of concerted efforts to predict the time, place and severity of the disasters. Apart from advanced weather forecasting models, data mining models also have been used for the same purpose. Another line of research, has concentrated on disaster management, appropriate flow of information, channelizing the relief work and analysis of needs or concerns of the victims. The sources of the underlying data for such tasks have often been social media and other internet media. Diverse data are also collected on regular basis by satellites, wireless and remote sensors, national meteorological and geological departments, NGOs, various other international, government and private bodies, before, during and after the disaster. The data thus collected qualify to be called ‘Big Data’ because of the volume, variety and the velocity in which the data are generated.
A brief technical description of some of the major natural disasters is as follows:
-
•
Earthquake: A sudden movement of the earth’s crust, causing destruction due to violent activities caused due to volcanic action underneath the surface of the earth. 55% of India’s landmass are in seismic zone III–V.
-
•
Landslide: A sudden collapse of the earth or mass of rock from mountains or cliff due to vibration on the earth’s surface. In India the northern sub-Himalayan region and Western Ghats are prone to landslides.
-
•
Cloudburst: It is an extreme form of unpredicted rainfall in the form of thunder storm, hail storm and heavy precipitation which is short lived. Unseasonal heavy rainfalls are common in India. A devastating effect of it was the flash flood in North India in 2013 that killed thousands of pilgrims and animals.
-
•
Storm: A bad weather in the form of rain or snow caused by strong winds or air currents formed due to unexpected changes in air pressure on the earth’s surface. Cyclones are common in various parts of India, especially the coastal regions that leave long lasting and expensive damages to human lives and properties.
-
•
Flood: An overflow of huge water masses beyond normal limits over dry land. Every year, millions of human lives, cattle and agricultural crops are destroyed in India due to lack of planning and improper weather forecasting.
-
•
Tsunami: High sea waves that are large volumes of displaced water, caused due to an earthquake, volcanic eruption or any other underwater explosions. The 2004 Tsunami that hit parts of the southeastern coast of India had devastating effects on the mainland and Andaman and Nicobar Islands.
-
•
Volcanic eruption: It is a sudden, violent discharge of steam, gases, ashes, molten rocks or lava from the surface of the earth that are ejected to heights and spread for several miles. Underwater volcanoes on the islands surrounding the landmass of India are common. However, they have not imposed significant damages to the mainland till now.
The unique contributions of the paper are as follows:
-
•
A comprehensive summary of different data mining techniques applied to various tasks pertaining to the natural disasters.
-
•
A detailed account of various types and sources of data for each category of task and disaster.
-
•
A brief account of disaster management ‘status-quo’ from Indian context.
-
•
A brief review of suitability of ‘Twitter’ as a data source.
-
•
A presentation of proposed architecture to streamline disaster management.
The organization of the paper is as follows: In Section 2, natural disasters have been discussed with focus on India; a brief description of the existing disaster management structure is also outlined. In Section 3, the broad categorizations of the tasks that can be achieved with respect to natural disaster are presented in detail. In Section 4, granular levels of tasks are enlisted with respect to the major type of tasks discussed in Section 3. Details of the tasks, data used in the task, data mining methods used, country or region have also been discussed. In Section 5, a structured view of different types of required data and their corresponding sources has been discussed. A short review of twitter and other Internet resources as data source has been discussed, along with their application for natural disaster in Section 6. In Section 7, a process flow and architecture of a disaster management system have been proposed. Section 8contains, conclusion with the direction of future work.
2. Natural disaster from an Indian context
India is vulnerable to various natural disasters due to its unique geo-climatic condition as a result of its geographical location. This subcontinent is surrounded by water bodies on three sides and the Himalayas on the North. The country has been hit approximately by 8 natural calamities per year and there has been about 5 times increase in frequency of natural disasters in the past three decades. The calamities that affect the country can be categorized as follows: 57% landmass is prone to earthquakes, 12% floods (about 40 million hectares of land is vulnerable to floods) and 8% are prone to cyclones. Table 1records such disasters for last 15 years.
Table 1. Natural disasters in India in last 15 years.
| Disaster Type | Year | Origin (India) | Tolls |
|---|---|---|---|
| Earthquake | 2001 | Gujrat | 20,000 |
| 1999 | Chamoli | 150 | |
| Cyclones | 2012 | Tamil Nadu | 20 |
| 2011 | Tamil Nadu | 41 | |
| 2010 | Andhra Pradesh | 32 | |
| 2009 | West Bengal | 100 | |
| 1999 | Orissa | 15,000 | |
| Tsunami | 2004 | Indian Ocean | 230,000 |
| Floods | 2007 | Bihar | 41 |
| 2005 | Mumbai | 5,000 | |
| Cloud Burst | 2014 | Jammu & Kashmir | 4,500 |
| 2013 | Uttarakhand | 5,700 | |
| Landslides | 2014 | Manlin, Pune | 28 |
| 1998 | Malpa, Manasarovar Yatra | 380 | |
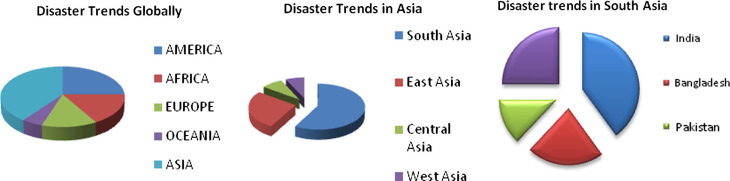
Asia, tops in terms of number of disaster events among the continents. Close to 60% of the disasters in Asia are originated in South Asia and 40% are originated in India. In the below figure (Fig. 1), the above statistics are displayed.
 Figure 1. Disaster trends across the globe.
Figure 1. Disaster trends across the globe.India is a victim of natural disasters every year and the loss of lives and properties adds up to millions of rupees which this country cannot afford to lose. There are certain reasons for such poor disaster management procedures followed in this country.
-
•
Inadequate early warning system.
-
•
Poor preparation before the disaster occurs.
-
•
Inadequate and slow relief operation.
-
•
Lack of proper administration.
-
•
Slow process of rehabilitation and reconstruction.
-
•
Poor management of finances for relief work.
-
•
Lack of effective help to victims.
The apex body that handles disaster management in India is the National Disaster Management Authority (NDMA) whose Chairman is the Prime Minister himself. Similar authorities are also set up at state and district levels which are respectively headed by the Chief Ministers and Collectors or Zilla Parishad Chairperson. The Natural Urban Renewal Mission has been set up in 70 cities due to the recent unprecedented weather conditions in major metros and megacities. Need of research to predict, prevent and reduce means of losses from a disaster is far from over. Over 100,000 Rural Knowledge Centers (or IT Kiosks) have to be established for meeting the need for spatial E-Governance and therefore offering informed decisions in disaster prone areas to improve the response time and type of relief aid offered to the victims on time. National disaster management structure is depicted in Fig. 2.
 Figure 2. Disaster management structure India.
Figure 2. Disaster management structure India.3. Broad category of tasks with respect to natural disasters
In this section, broad categories of tasks that can be solved using different types of data have been discussed. We can classify the objectives of the tasks, in the following three major categories:
-
•
Prediction: These sets of tasks involve prediction of the natural disaster, disaster prone area and different attributes of a natural disaster that can occur. Basically these tasks involve prediction or forecasting of time, place and magnitude of the disaster.
-
•
Detection: These sets of tasks involve detection of the natural disaster promptly after it has occurred. Literature studies indicate that the social sensors in terms of tweets and other social media websites report a natural disaster much faster than the observatories.
-
•
Disaster management strategies: These methods deal with identification of different entities that are taking part in combating a disaster so that communication is enhanced, appropriate concern of the affected people is identified and distribution of relief items is optimized.
Another branch of study deals with carrying out the psychological and behavioral changes over affected regions after the disaster.
In many cases, the classification stated above is overlapping. As an example, it can be surely argued that, detecting the natural disaster helps in disaster management strategies. Even the psychological studies can give lot of insight to disaster management strategies. So the classification is based on the direct objective of the task involved. There are some rare cases which fall in a borderline.
Prediction: There is no doubt that this would be the most ‘ideal’ problem to solve. But very often, this is not a problem that can be solved with available data and techniques. However, it is possible to predict, the areas which are susceptible to a particular type of disaster, let us say, landslide or flood. The prediction techniques have been seen to be of more use for predicting various characteristics of a natural disaster, which has occurred. As an example, the techniques can be used to predict the magnitude of an earthquake, track and intensity of a cyclone, etc. Analysis of various spatial and temporal data is often needed for such tasks. Though handful, another branch of research has focused on using unusual animal behavior to predict a natural disaster.
Detection: Often the meteorological observatories detect the natural disaster, but the news of the detection takes a long time to be communicated to proper authorities with the exact location of the detection.
Disaster management strategies: These sets of tasks are involved in forming appropriate disaster management strategies. An example of such tasks is identifying critical entities for disaster management, identifying proper communication study, and identifying the needs of the disaster affected area. Social media data are very important in these types of tasks.
The aim of disaster management should be the following:
-
•
Minimize casualties.
-
•
Rescue victims on time.
-
•
Offer first aid instantly.
-
•
Evacuate people and animals to safe places.
-
•
Reconstruct the damages immediately.
4. Data, models, tasks
In this section, a summary has been enclosed highlighting the granular level tasks corresponding to the major type of tasks such as prediction, detection and disaster management. An account of model/techniques has been given along with the data used and the country of the disaster/research.
The findings are summarized in Table 2a, Table 2b, Table 2c, Table 2d, Table 2e, Table 2f, Table 2g, Table 2h. The tables are divided as per the natural disasters; separate tables are presented for earthquake (Table 2a), cloudburst (Table 2b), flood (Table 2c), landslide (Table 2d), volcanic eruption (Table 2e) storm (Table 2f) and tsunami (Table 2g). Table 2h represents generic efforts without focus on a specific type of disaster, which have been covered.
Table 2a. Earthquake data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Prediction | Predict magnitude of earthquake [5] | Particle swarm optimization | Seismological data | China |
| Focus on abnormal animal behavior, rather than the geophysical indicators. The study has been done mainly in Japan, China and USA. Animals are much more sensitive to the change in electric field precursor to the earthquake [6] | NA | NA | Japan, China, USA | |
| Predict magnitude of earthquake [7] | Neural network | Seismological data | USA | |
| Building a data warehouse for earthquakes, for uniformity of data and structure of data for a uniform interchange and better decision making [8] | Ontology, star schema, data warehouse | Seismological data | All over the world | |
| Predict earthquake based on time series data [9] | Nonlinear time series and fuzzy rules | Seismological data | All over the world | |
| Predict earthquake from historical data and also propose a grid system for distributed processing and better information interchange [10] | Feature generation and clustering | Seismological & GIS data | USA | |
| Detection | Discover major earthquakes faster than seismological observatories [11] | Text mining | USA | |
| The affected area citizens visit web pages of the Swiss Seismological Service, by doing an IP tracing and volume analysis, the affected regions can be tracked easily [12] | Regular log mining techniques | Web server logs | Switzerland | |
| To detect earthquake from social sensors i.e. twitter, do a spatial, temporal analysis and send notification much faster than that of the Japan Meteorological Agency (JMA) [13] | Temporal Analysis, Kalman filter | Japan | ||
| Disaster management | A temporal analysis of peoples need after the earthquake from blogs and social media. This can make the relief operation more effective [14] | Text Mining, latent semantic analysis (LSA), time series | Blogs & social media data | Japan |
| Behavioral and social analysis | To study general peoples reaction after a natural disaster like an earthquake and how long they take to subside to normal level [15] | Time series, text processing | Japan | |
Table 2b. Cloudburst data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Prediction | Observe different parameters of climate from the earth science data, to find out whether there was enough indication of the Uttarakhand disaster [16] | Anomaly detection, time series | Earth science data | India |
| To leverage OLAP structure to store metrological data and analyze them to identify cloudbursts [17] | OLAP cubes, K means clustering | Meteorological data | India | |
| Real-time newscast and prediction of rainfall in case of extreme weather like cloud burst from Doppler weather radar data [18] | Mesoscale model | Doppler Weather Radar data (DWR) | India |
Table 2c. Flood data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Prediction | Build a model and select appropriate parameters to assess the damage from flood [19] | Decision tree | Hydrological data, remote sensing data, GIS | Germany |
| To build a model to find susceptible flood regions based on spatial data [20] | Logistic regression and frequency ratio model | Meteorological data (digital elevation model), river, rainfall data, etc. | Malaysia | |
| To build a model to predict monsoon flood (1 day ahead). The built system gave better results than existing auto regressive models [21] | Wavelet transform, genetic algorithm, artificial neural net | Hydrological time series data | India | |
| Build a system for flood forecast for medium- to large-scale African river basins (before 2 weeks) [22] | Probabilistic model & ensemble | Hydrological data | Africa | |
| Build a flood routing model based on past data [23] | Muskingum flood routing model, Cuckoo Search (for parameter values and calibration) | Hydrological and hydraulic data | All world | |
| Disaster management | A study of tweets during various floods was done to identify key players. The study shows the effect of local authority involvement in successfully tackling a disaster [24] | Text mining methods | Australia | |
Table 2d. Landslide data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Prediction | Build a classifier to identify landscapes to landslide susceptible areas based on soil properties, geomorphological, and groundwater conditions, etc. [25] | Discrete rough set and C4.5 decision tree | Remote sensing data and GIS | Taiwan |
| To build a classification model to predict land slide. The various factors considered are rainfall, land use, soil type, slope, etc. [26] | SVM, Naïve Bayes | GIS (rainfall, land use, soil type, slope and its) | India | |
| A generic note on usefulness of data mining/machine learning models in predicting place and time of a land slide [27] | NA | NA | All over the world | |
| Build a prediction model based on an inexpensive wireless sensors placed on susceptible regions [28] | Distributes statistical prediction method | Wireless sensor data | India | |
| To build a model to identify areas of shallow landslide [29] | Spatial distribution | Geomorphologic information and hydrological records | Taiwan | |
| Predicting landslide based on past data [30] | Back propagation neural network, genetic algorithm, simulated annealing | China |
Table 2e. Volcanic eruption data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Prediction | Analysis of multivariate time series data to understand the state of the volcano and potential hazard assessment [31] | Multivariate time series clustering | Geophysical data through monitoring network | Italy |
| To monitor and predict trajectories of volcanic ash cloud, to minimize air crash [32] | Not mentioned | Plume height, mass eruption rate, eruption duration, ash distribution with altitude, and grain-size distribution | USA |
Table 2f. Storm data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Prediction | Take the data of current storm and compare with the historical & synthetic storms using storm similarity index (SSI) from the databases to understand the effect. Visualization of the storm path is done on Google Earth. The study was done on two previous storms Katrina and Camille [33] | Data mining techniques | National Hurricane Center (NHC) | USA |
| To predict cyclone track data for coming 24 h, based on past 12-h locations at six hourly intervals besides the present position about the latitude and longitude [34] | Artificial Neural Network (ANN) | 32 Years tropical cyclone data on Indian ocean from joint typhoon warning center (JTWC), USA | India | |
| Detect storm surge using no linear model from data collected at coastal station [35] | Time series and chaos theory | Water level, surge, atmospheric pressure and wind speed/direction data from seven coastal stations along the Dutch coast are monitored and provided by the North Sea Directorate | Netherland | |
| Behavioral | Study effect of the hurricane ‘Hugo’ on life events birth, death, divorce, etc. [36] | Statistical analysis | Life event data from all the counties of South Carolina | USA |
| Disaster management | Identify the concerns of people, stay duration of the ‘concerns’, conduct analysis by gender [37] | Sentiment analysis, normal text processing techniques | USA | |
| Analysis of people’s sentiment, after Hurricane Sandy and also to gather and decimate important information through social media [38] | Text processing techniques | USA | ||
| Analysis of public behaviors during and after a disaster through visualization and spatial temporal analysis [39] | Spatial, temporal techniques, visualization | USA | ||
Table 2g. Tsunami data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Disaster management | Viability of use of twitters by government agencies, to inform public about natural disaster. It was compared against traditional sources and proved its value as a complementary source [40], [41] | Text processing techniques | Indonesia, USA | |
| Prediction | Build an early warning system for Tsunami [42] | Flood filling algorithm, classification algorithms | Bathymetry data, Seismic data, sea wave conditions, web service and API to collect the data | Indonesia |
Table 2h. General data, model and task summary.
| Task | Detailed objective | Model techniques used | Data source, type | Country |
|---|---|---|---|---|
| Disaster management | Build a tool to extract important information from tweets for relief workers [43] | Text processing techniques | USA | |
| Build a system, for disaster discovery and humanitarian relief based on tweets. The system consists of a stream reader, a data storage and a visualization module. [44] | SVM, LDA, topic clustering | USA | ||
| Prediction | Build a geo hazard database for early prediction system, by using the Google news service. Geo tagging is done for geo referencing. The purpose is using this database extensively for disaster management [45] | Text processing | Google news service, RSS feed | Italy |
In the tables referred above, different research directions in combating natural disaster have been discussed. This is a multidisciplinary activity needing experts from environmental science, geology, meteorology, social science, computer science, etc. The above list is not exhaustive, but an effort has been made to cover last 10–12 years data in this section. Here are few of our observations:
-
•
Twitter as a source has become important for real time detection and understanding of the need and concern of the affected people. Ten out of the forty papers we reviewed above use twitter as the data source. Interestingly, we did not find any referential work, where twitter has been used in an Indian context.
-
•
It is also observed, though India has a much higher loss in terms of human life and property, and adequate research as in countries such as USA has not been done in India (Fig. 3).