Artificial intelligence (AI) in transportation infrastructures
Due to the inherent complexity of geotechnical materials, researchers tend to shift from traditional technical solutions to more sophisticated approaches supported on Artificial Intelligence (AI) methods to solve several geotechnical problems and evaluation issues [22], [60]. Geotechnical problems are characterized by high uncertainties and involve many factors that often cannot be directly determined by engineers. Moreover, following advances in Information Technology (IT), during the last decades the amount of digital data collected from geotechnical works has increased significantly. These data hold potential predictive and prescriptive knowledge that can be extracted using AI methods. Indeed, in the end of the 20th century, David Toll [83] compiled some AI systems that have been developed for geotechnical applications, where Artificial Neural Networks (ANNs) were identified as one of the mainly used AI algorithms. More recently, updated compilations have been published [18,32] underlying the strong impact of AI in the field of geotechnics. In particular, the review paper written by Ebid [18] identified more than 620 applications of AI in geotechnical tasks during the last 35 years. amongst them, at least 250 were directly related to transportation infrastructures issues. The survey of Ebid [18] highlights that Machine Learning (ML) algorithms (an AI subfield), are capable of capturing the potential data correlations without any prior assumptions [85,93,94]. Also, over the series of the International Conference on Information Technologies in Geo-Engineering - ICITG [81,24,82], a high number of AI applications covering different geotechnical fields has been presented and discussed, showing a strong AI impact in geotechnics.
The AI field is currently impacting the world due to three main phenomena [14]: the continuous increase of computational power, the rise of big data and the development of sophisticated algorithms (e.g., Deep Learning) to extract useful knowledge from data. Given the success of AI, several data related terms, under distinct perspectives, have been proposed, such as: Analytics, Data Mining (DM), ML, ANN, Deep Learning (DL) and Evolutionary Computation (EC). The term Analytics, often used as a synonym for DM, refers to the extraction of useful knowledge from raw data [63]. Predictive and prescriptive analyses are the two most important analytics types [3], [15]. The former uses data-driven models (e.g., via ML) based on past data to predict the future, while prescriptive analytics measure the effect of different decisions, allowing to select the best current course of action. Both analytic types are valuable for geotechnics. In particular, ANN (including DL, which is a special form of ANN) and Support Vector Machines (SVM) are a popular ML algorithms for producing predictive geotechics models. As for EC, it is an AI subfield focused on iterative algorithms for optimization tasks, quickly locating quality regions within a large search space, thus being valuable for prescriptive analytics [10].
The management of transportation infrastructure is a key asset for any country, which faces several complex and challenging geotechnical problems, during its the design, construction and maintenance phases. To address these problems, advanced predictive and prescriptive AI algorithms have been implemented, aiming to find an efficient solution. In this paper, we particularly discuss three transportation geotechnics case studies, showcasing how AI algorithms can support and enhance decision making. This paper is organized as follows. Section 2 introduces key concepts related with predictive and prescriptive AI models used in the three analysed case studies. Then, Sections 3, 4 and 5 summarise the main findings of recent predictive and prescriptive AI applications in transportation infrastructure field, namely on earthworks, soil improvement by jet grouting technology and engineered slopes stability identification. Finally, Section 6 concludes the paper and discusses prospective advances in this topic.
Predictive and prescriptive AI methods
ML algorithms [27] are capable of capturing the potential correlations amongst information without any prior assumptions [85,[93], [94], [95]]. Nowadays, there are available several supervised learning ML algorithms that allow to build predictive models from past data, each one with its advantages and limitations [5,17,26]. In fact, many of them have already been successfully applied to solve complex geotechnical problems [[18], [40]]. Amongst the different ML algorithms, ANNs and SVMs are two successful supervised modelling AI techniques [33]. ANNs are a computational technique inspired by the nervous system structure of the human brain [36,91]. SVMs are a very specific class of algorithms characterized by the use of nonlinear kernels [9], which implicitly map the input space into high-dimensional feature space. The SVM algorithm searches for the optimal linear separating hyperplane related to a set of support vector points [67]. Despite the differences, both algorithms present flexible and powerful learning capabilities, being capable of modelling a wide range of data mapping functions, including complex nonlinear relationships. Moreover, both ML algorithms tend to product robust results even when dealing with noisy data. Also, these algorithms can address both regression and classification tasks. For a baseline comparison, in some of the case studies reported in this paper, the classical Multiple Regression (MR) algorithm was also tested [16].
Depending on the nature of the target variable, resulting in a regression (if numeric) or classification (if categorical) task, different metrics need to be adopted to assess the predictive performance of the models. Concerning to regression tasks, there are three popular performance metrics: the Mean Absolute Deviation (MAD), the Root Mean Squared Error (RMSE) and the Pearson correlation coefficient (R2) [75]. The first two metrics should present lower values, and R2 should be close to the unit value. The main difference between RMSE and MAD is that the first measure is more sensitive to extreme values or outliers. The Regression Error Characteristic (REC) curve [4], which plots the error tolerance on the x-axis versus the percentage of points predicted within that tolerance on the y-axis, can also be plotted to analyse and compare the quality of the predictions produces by different regression models. For classification tasks, three popular predictive performance metrics are: Recall, Precision and F1-score [77]. Often, there is a trade-off between Recall and Precision. The Recall measures the ratio of how many cases of a certain class were properly captured by the model, while the Precision measures the correctness of the model when it predicts a certain class. The F1-score represents a particular trade-off between the Recall and Precision of a class, corresponding to the harmonic mean of Precision and Recall. For all three metrics, the higher the value, the better are the classifier, which can range from 0 to 100%.
To access the data-driven model generalization capability, several validation approaches can be adopted [28]. A popular validation approach is the k-fold cross-validation, which divides the available data into k different subsets, resulting in k training and testing iterations. During the k iterations, one different subset is used for testing, while the remaining data is used to train the ML model. In the end, all of the data are used for either training and testing. It should be noted that the evaluation metrics are always computed on test unseen data (as provided by the cross-validation procedure).
Besides having a high-quality predictive capability, data-driven ML models should be easily understood by humans, a concept known as Explainable AI (XAI). Having a good XAI or human model interpretability is a fundamental step towards a better understanding of what the model has learned, helping to increase the trust of such model by the decision maker. One interesting way to obtain a XAI, thus opening complex ML models such as ANN or SVM, is to quantify the relative importance of the input variables, as well as its overall effect on the output by adopting a sensitivity analysis. With this information it is possible to plot the relative importance barplot and the variable effect characteristic (VEC) curve [11] respectively. For a given input variable, the VEC curve plots the values of the attribute at the L level (x-axis) versus the sensitivity analysis responses (y-axis). To enhance the visualization analysis, several VEC curves can be plotted in the same graph. In such case, the x-axis is scaled (i.e., within [0,1]) for all xa values. This procedure can be applied after the training phase of any supervised DM model and it provides a systematic analysis of the ML model responses to changes in a given input [11].
Once a high quality generalization ML model is obtained, the ML can be easily used to perform predict future values of relevant geotechnics variables. These predictions, combined with known values (e.g., collected in a database) can be used to estimate several infrastructure management indicators, such expected construction time or maintenance costs. The distinct management decisions (e.g., set maintenance budgets) can be represented in a computational form, which defines a search space that can be used by EC, aiming to maximize or minimize different goals (e.g., reduce costs, increase the quality of construction roads, reduce environmental impact). Thus, predictive ML models can be combined with EC, aiming to provide valuable prescriptive geotechnics analytics, such as shown in Section 3.2.
Earthworks
Equipment productivity
The ability to accurately estimate the productivity/work rate of mechanical equipment is one of the main factors that supports and potentiates both an efficient and an effective planning of earthworks projects. Indeed, bearing in mind the specificities of earthworks, one can easily infer that it is inherently comprised by a production line through which geomaterials are transported and processed into loadbearing-capable foundations. This production line is directly comparable to an outdoors factory-floor, in which the machines that process the raw material into the final product are the heavy mechanical earthworks equipment, namely the equipment responsible for the excavation, transportation, spreading and compaction tasks (amongst other situational and/or intermediate tasks). In turn, the raw material that feeds this production line is the excavated geomaterial, while the final product is represented by embankments capable of bearing the load of a future structure, thus serving as (part of) its foundation.
An inherent characteristic of production lines lies in the fact that the speed at which it processes materials is not only a function of the work rate of each machine, but also of the ability to synchronize the work rate of each station so that the whole production line is as homogeneous as possible in this regard. This prevents teams at a given station (or work front) to work too fast or too slow, which typically incurs in an overflow of material or in idle times for downstream stations, respectively. Naturally, the work rate of a given equipment is not solely dependant on its own characteristics. In fact, it varies greatly depending on outside parameters, such as the types of materials being handled, the skill of the operator, climacteric and humidity conditions, and, as previously mentioned, the productivity of upstream and downstream processes. Thus, accurately estimating productivity-related aspects and parameters is a first essential step for any design and planning initiative in any construction project, and even more so in projects that rely greatly on heavy mechanical equipment, as is the case of earthworks.
In order to achieve this goal, several different ML models were applied to a earthworks activity log comprising part of a past highway construction project database. Table 1 summarizes the available earthworks information featured in the original database. From these, additional variables can be inferred such as transportation distance between excavation and embankment fronts, number and types of equipment active in each work front, specifications and classification of equipment pieces, and classification of geomaterial types.
Table 1. Available earthworks data from highway construction project.
| Equipment data | Spatial data | Productivity data | Other |
|---|---|---|---|
| Equipment identification platesEquipment types | Equipment location dataWork front location data | Daily processed volumesDaily work hours | DateAtmospheric conditions |
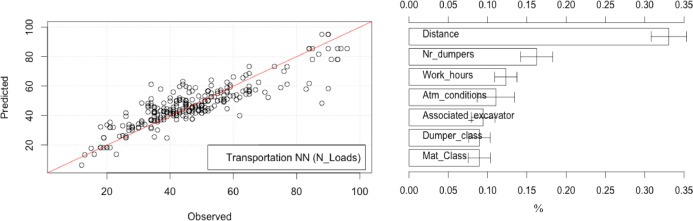
Due to the nature and the large volume of data and variables, direct implementations of ML models were unsuccessful. In fact, the adoption of a high number of variables typically results in excessive complexity in the discovery of relations and patterns in the data, ultimately hampering the model's predictive capabilities. As such, the data was divided into two subsets for two different DM models. The first focused on compiling all the variables with influence on the productivity of excavation and transportation teams (i.e. excavators and dumper trucks) to maximize predictive power of these types of equipment in different work conditions. In turn, the second model addressed the estimation of spreading and compaction teams. Since the aim was to impart into the predictive models the sequential nature of the earthworks production lines, the models were built in a cascade prediction framework. This means that the output from the first model was used as input for the second, allowing the latter to take into account the productivity of upstream processes in the estimation of spreading and compaction work rates in different work conditions. Fig. 1 and Fig. 2 respectively depict the obtained results for the excavation/transportation model and the spreading/compacting prediction models (the closer the predicted values are to the diagonal line, and thus to the actual observed values, the better the accuracy of the prediction), including the variables used in their construction and their relative importance [57]. As one can infer from the analysis of these figures, ANN exhibited a very good fit for the data in terms of predictive ability in both cases, though the compaction model (Fig. 2) shows a higher prediction accuracy.
 Fig. 1
Fig. 1 Fig. 2
Fig. 2The results output by the first model (excavation and transportation teams) demonstrate its good predictive capabilities regarding the number of daily number of loads by the transportation teams (i.e., number of round trips carried out by dumper trucks to load geomaterials in excavation fronts and unload them in embankment fronts), featuring RMSE and R2 values of to 8.325 and 0.855, respectively, which denote a very good fit in a real-world data context. However, it is important to mention that the data corresponds to a single construction site, in which the variability of geomaterials is low. As such, this is the main reason behind the fact that the variable corresponding to the material type (Mat_Class) displays a relatively low importance when compared to other variables. Indeed, the project site is mostly comprised of soil-rockfill mixes with similar requirements regarding excavation, and thus also a similar effect on the work rate of the excavation and transportation teams. Consequently, despite its counter-intuitiveness, the predictive model is unable to understand the real significance that different geomaterials would have on the actual productivity of excavation and transportation teams.
Bearing in mind that the output of the first model regarding excavation and transportation teams (N_Loads) is one of the most relevant variables in term of importance for the second model (Fig. 2), the latter displays a RMSE and R2 values of 26.377 and 0.980, respectively, regarding the prediction of the spreading and compaction work rate (m3/h). At first glance, one can easily infer that the same issues regarding the low variability of the geomaterials present in the data have also had a similar effect on the importance of variables related to material types (Mat_class) for this model.
However, a deeper analysis also suggests that an additional underlying issue with the data, which may be translated in a potential limitation of the design and resource management approach adopted for this project. Indeed, the fact that high number of variables which would be expected to have a high importance in the prediction of spreading and compaction productivity instead display a low importance ratio, coupled with the extremely high importance ratio associated to the upstream processes output by the first model (N_Loads), provides an indication that these upstream processes may be hindering the potential productivity of the spreading and compaction teams. This is a somewhat common occurrence in complex production lines such as these, where the high uncertainty inherent to earthworks activities causes upstream processes to work in a lower productivity than the spreading or the compaction teams. This typically incurs in idle times, in which compactors have to interrupt their activity while waiting for more material to be brought by the transportation teams to the embankment work front. Such can be an indication that the current configuration of the earthworks production lines needed to be adjusted so that an optimal resource management status could be achieve, in which all active equipment can work at their maximum potential work rate.
Paradoxically, these results simultaneously demonstrate how powerful machine learning can potentially be in this field (especially concerning the accuracy of productivity estimates for excavation and transportation teams, stemming from the first model), and at the same time how much it can be limited by a faulty database. As a matter of fact, not only is the low variability of geomaterials hindering the predictive capabilities of each model, but also the knowledge generated by the second cascade prediction seems to indicate that equipment allocation in the production lines is working below optimal productivity values. Nonetheless, note that before applying these models, it was not obvious and there was no indication that the adopted planning methodologies were not effective, and as such, even though the estimation capabilities of the second model may have been impaired, it is still important to note the significant knowledge was gained by the implementation of ML models to this database and this context.
Equipment allocation optimization
Notwithstanding database-related limitations such as the ones discussed above, predictive models may still be taken a step further towards integration in more complex systems, capable of addressing several of the issues found in earthworks constructions. Indeed, as previously mentioned, the capability to accurately estimate the productivity of active equipment, even if partially, can be leveraged upon to enhance the design and planning of this types of projects from a problem optimization perspective.
Generally, optimization systems rely on an optimizer algorithm, which searches for potential solutions for a problem, working in parallel with an evaluation function, which is meant to punctuate each possible solution in order to establish a measure of preferences over decision objectives. Bearing in mind the most common optimization objectives are related to cost and duration minimization, one can easily infer the significance of the accurate estimation of productivity, as it directly translates evaluation of the time that earthwork resources (i.e., mechanical equipment) require to complete earthwork tasks. Thus, an optimization algorithm can constantly leverage on the knowledge output by predictive models to assess different resource allocation solutions in terms of cost and time. As far as optimization algorithms are concerned in the context of earthworks applications, metaheuristics techniques have grown in popularity due to their ability to deal with large search space regions under a reasonable use of computational resources. EC is one of the most successful AI optimization based techniques [10], while other relevant optimization methods include Swarm Intelligence (SI) algorithms, such as Particle Swarm Optimization (PSO) and Ant Colony Optimization, and fuzzy logic algorithms (FLA).
Though lacking in real-world applications, the literature features the development of several optimization systems, which can be divided in function of their project application phase. While predictive optimization is applied during planning and design phases requiring all the inputs to be provided by the decision makers or basing it on historical data, reactive/online optimization has the ability to be applied during construction phase, due to the integration of any type of information acquisition system capable of extracting data from the construction site. Both of these types of systems are susceptible of being supported by parameter estimation models, which are typically developed in pre-design or design phases, as shown in Table 2.
Table 2. Matrix of application areas of existent intelligent earthwork system types.
| Underlying Technology | Data acquisition and parameter estimation (pre-design phase) | Planning & Design phase (predictive optimization) | Monitoring & Control phase (reactive optimization) | |
|---|---|---|---|---|
| Machine learning / Data driven systems |
Type 1 [19], [29], [31], [43], [55], [61], [62], [64], [66], [69] |
|||
| Optimization systems | GA and SI |
Type 2 [1], [8], [35], [37], [44], [45], [46], [47], [51], [54], [56], [58], [89], [92] |
Type 5 [49], [50], [59] |
|
| FLA and P/T nets |
Type 3 [6], [7], [21], [41], [90] |
|||
From amongst these, the systems proposed by Parente et al. [58,59] especially feature the combination of predictive models and optimization algorithms to address not only cost and time during design and construction, but also environmental aspects. In fact, any variable can be used as such given that it is susceptible to estimation by resorting to predictive models, or alternatively mathematically quantifiable. This is one of the main aspects that depict how powerful the combination of these technologies is, since, depending on the availability of data, the evaluation functions and minimization objectives can account for an extremely broad range of variables. Noteworthy variables may be related to environmental aspects, such as greenhouse gas emissions, and even social aspects, such as job creation or regional economic impact. Ultimately, such systems represent a relevant step towards enabling the current sustainable construction trends, as they can effectively support the design of construction projects by approaching the three main pillar of sustainability, namely economic, environmental, and social [25], as depicted in Fig. 3.
 Fig. 3
Fig. 3Soil improvement by jet grouting
The increased demand for construction space, at a given point require the use soft soils. Typically, this implies that a previous treatment is necessary in order to convert the latter into a proper foundation that fulfil the adequate soil properties. amongst the several techniques for soft soil improvement [38,42,88], Jet Grouting (JG) is one of the most versatile, as it can be applied on both clayed and granular soils, in confined spaces (e.g., inside buildings), and results in increased strength and stiffness of the treated soil, while also improving its permeability [52,53,86,87]. However, its design is a complex task involving multiple variables, ranging from soil properties to injections parameters. Recently, this problem was approached through the application of DM algorithms [70], namely ANN and SVM, as well as MR for a baseline comparison. The main findings of this research are summarized below.
This study comprises two groups of experiments. One related to laboratory mixtures and another one covering field samples. Table 3 summarises the input variables considered in Uniaxial Compressive Strength (UCS) and Young Modulus (E0) studies of both laboratory and field mixtures, as well as for column diameter (D) study. A detailed characterization of the databases used in all these experiments can be found on Tinoco [70].
Table 3. Input variables considered on jet grouting properties design using a data driven approach (a complete description of each input variable can be found on Tinoco [70]).
| Variables | Laboratory | Field | |||
|---|---|---|---|---|---|
| UCS | E0 | UCS | E0 | D | |
| t (days) | ✓ | ✓ | ✓ | ✓ | ✗ |
| Civ | ✓ | ✓ | ✓ | ✓ | ✗ |
| W/C | ✓ | ✓ | ✓ | ✓ | ✗ |
| s | ✓ | ✗ | ✗ | ✗ | ✗ |
| n/(Civ)d | ✓ | ✓ | ✓ | ✓ | ✗ |
| %Sand | ✓ | ✓ | ✗ | ✗ | ✓ |
| %Silt | ✓ | ✓ | ✗ | ✗ | ✗ |
| %Clay | ✓ | ✓ | ✓ | ✗ | ✓ |
| %OM | ✓ | ✓ | ✗ | ✗ | ✗ |
| JS | ✗ | ✗ | ✓ | ✓ | ✓ |
| 1/ρd | ✗ | ✗ | ✓ | ✓ | ✗ |
| e | ✗ | ✗ | ✓ | ✓ | ✗ |
| ω | ✗ | ✗ | ✓ | ✓ | ✗ |
| WS | ✗ | ✗ | ✗ | ✗ | ✓ |
| Dgrout | ✗ | ✗ | ✗ | ✗ | ✓ |
| FR | ✗ | ✗ | ✗ | ✗ | ✓ |
| Pgrout | ✗ | ✗ | ✗ | ✗ | ✓ |
| IMPgrout | ✗ | ✗ | ✗ | ✗ | ✓ |
Uniaxial compressive strength
Concerning the UCS study, Fig. 4 depicts the models’ accuracy for filed samples. For laboratory formulations, the achieved performance is superior as discussed on Gomes Correia et al. [23]. In this figure, additionally to the relation between observed and predicted values based on SVM algorithm (points), the REC curves of all three trained algorithms (ANN, SVM and MR) are also plotted. Moreover, metric values of MAD, RMSE and R2 of SVM model (from here termed as SVM-UCS.Lab and SVM-UCS.Field, respectively for laboratory and field mixtures) are also included in the figure. From the analysis of the REC curves, the higher performance of the SVM algorithm is clear, immediately followed by ANN.
 Fig. 4
Fig. 4When comparing SVM algorithm performance on laboratory and field mixtures [23], a significantly better performance can be easily inferred on laboratory formulations, with an R2 close to 0.93. This behaviour is expected if taking into account the level of complexity involving each type of mixture. While a laboratory formulation is prepared under a controlled environment, the uncertainty associated with field samples is higher both in terms of soil properties and in the effect of the construction process. Nevertheless, even under these conditions, an R2 higher than 0.50 was achieved by SVM-UCS.Field model. Moreover, it should be noted that 81% of the prediction shows an error lower than 2 MPa, which represents a remarkable achievement.
To better understand the developed models, a detailed sensitivity analysis [11] was carried out. This procedure allowed for the identification of the key parameter on UCS prediction [72], [74] as plotted on Fig. 5, which is of particular relevance from an engineering point of view.
 Fig. 5
Fig. 5Fig. 5 compares the relative importance of each input variable in UCS prediction for both laboratory and field mixtures, according to SVM-UCS.Lab and SVM-UCS.Field models. As expected, in the field mixtures study JS presents the second highest importance in UCS prediction. On the other hand, it is observed that in both mixtures n/(Civ)d and t are between the most relevant variables, which is consistent with empirical knowledge related with soil-cement mixtures [12,30]. Moreover, it is also interesting to observe that Civ is much more preponderant for UCS prediction of laboratory mixtures than for field samples. In fact, Civ is around 10% more relevant in the laboratory mixtures in comparison to field mixtures. However, it should be also noted that in the field mixtures n/(Civ)d (that for simplicity also incorporates the cement content) is around 5% higher. Thus, in both mixtures, the cement content influence on UCS development, which represents one of the most relevant variables in soil-cement mixtures according to the empirical knowledge, presents a similar relative importance.
Another relevant observation taken from Fig. 5 is the relative importance of %Clay. While in the field mixtures this is the third most relevant variable, it plays a minimal role regarding UCS prediction of laboratory samples. However, it should be stressed that in the laboratory mixtures study, soil properties were contemplated not only in terms of %Clay, but also by %Sand, %Silt and %OM, which have an overall influence around 23%.
From Fig. 5, it can also be observed that, in UCS prediction of field mixtures, the four key variables according to SVM-UCS.Field model include one variable related to the soil type (%Clay), another related with the JG process (JS) and two other related to the JG mixture, namely its age and the n/(Civ)d relation, which combines the porosity and the cement content effect. In other words, to predict UCS of field mixtures, the models require information about the soil to be improved, how the improvement is performed, and the actual conditions of the obtained mixture.
In conclusion, in both cases SVM-UCS.Lab and SVM-UCS.Field models were able to learn the actual empirical knowledge related with JG mixtures was well as with soil cement mixtures in general [[84], [97]]. These achievements deserve a particular attention in the case of soilcrete mixtures since the accuracy of the SVM-UCS.Field model is not on par with the accuracy of the SVM-UCS.Lab model.
Bearing in mind that understanding the influence of each variable, particularly the most relevant ones, in the UCS prediction is also a fundamental aspect, the proposed methodology by Cortez and Embrechts [11] was applied for this purpose. In this context, Fig. 6 depicts the VEC curves of the four key input variables in UCS prediction of laboratory mixtures according to SVM-UCS.Lab model. As expected, all four variables have a non-linear effect regarding the UCS prediction. Moreover, while t and Civ have a positive impact in the UCS prediction, n/(Civ)d and W/C present a negative influence, which is in line with the empirical knowledge related with soil-cement mixtures. Moreover, the VEC curve of t shows a concave shape, which means that the mixture strength increases more quickly in early ages (up to 45 days time of cure), after which it slows down until it stabilizes [30,84]. The exponential shape of Civ VEC curve is also interesting to observe, depicting that the cement content is considerably more influential in UCS prediction of laboratory mixtures for Civ values higher than 45%. Lastly, it is possible to observe that n/(Civ)d and W/C VEC curves have a very similar effect (concave shape) on the UCS prediction of laboratory mixtures [39], tending towards approximate linearity for high values of either n/(Civ)d or W/C.
 Fig. 6
Fig. 6Concerning the study of field mixtures, Fig. 7 plots VEC curves for n/(Civ)d, JS, t and %Clay (the four key variables in soilcrete strength prediction). From its analysis, a predominant nonlinear effect in the UCS behaviour of soilcrete mixtures can be inferred, which fits the empirical knowledge on the subject. Thus, UCS increases with the age of the mixture according to an exponential law [12,84]. This convex shape indicates once again that the first days during the cure process are responsible for the main increase in strength of the mixture. On the other hand, the relation n/(Civ)d and the %Clay have a similar and negative impact in UCS prediction. This means that when increasing the mixture porosity or clay content, or decreasing the cement content, the UCS of the mixture will decrease. Furthermore, the highest values of UCS are achieved for mixtures produced with single fluid system, decreasing almost linearly for double and triple fluid system. This outcome makes sense if taking into account that when increasing the energy of the jet (from single to triple fluid system), the achieved distance is higher. Then, the content of cement by unit volume of soil is lower, leading to a decrease in the UCS of the produced mixture.
 Fig. 7
Fig. 7Despite the relevance and interest of the results above, improvements are still required. Particularly, the models’ dependence on final mixture properties should be avoided. Hence, new experiments need to be conducted in order to exclude the mixture properties dependence, namely mixture porosity and density, which can only be quantified ensuing the construction of JG columns and the collection of samples for laboratory analysis [71].
Young modulus
Similarly to what was developed for UCS prediction, the same three algorithms (ANN, SVM and MR) were also applied for elastic Young's modulus (E0) prediction of laboratory and field mixtures [73]. Fig. 8 illustrates the relationship between E0 experimental values versus predicted by SVM model for field samples (from now termed as SVM-E0.Field). Also here, a better performance was observed for laboratory mixtures (from now termed as SVM-E0.Lab), as discussed on Gomes Correia et al. [23]. The models performance assessed by metrics MAD, RMSE and R2 are also detailed in the picture. Moreover, SVM-E0.Field model is also compared with ANN and MR models through REC curves, showing once again the higher performance of SVM algorithm also in the stiffness study of both laboratory and soilcrete mixtures, although ANN have achieved a slightly better accuracy in stiffness prediction of laboratory formulations [23].
 Fig. 8
Fig. 8As in UCS study, a superior performance was observed on laboratory mixtures when compared to soilcrete mixtures [23]. Indeed, while for laboratory mixtures an R2 very close to the unit value (R2=0.96) was achieved, for soilcrete mixtures SVM-E0.Field model achieved an R2=0.53 in E0 prediction. However, it should be noted that for field mixtures an R2=0.53 can be seen as a remarkable achievement, due to the high number of variables involved and soils heterogeneity, which make JG mechanical properties prediction a very complex task.
Concerning the relative importance of each model's attribute in stiffness prediction, Fig. 9 compares the variables’ ranking according to SVM-E0.Lab and SVM-E0.Field models for laboratory and soilcrete stiffness prediction, respectively. From its analysis, one can easily observe that, for stiffness prediction of laboratory mixtures, n/(Civ)d and t are the two key variables, summing a relative importance of around 37%, which is identical to those on the UCS study. Moreover, soil properties (particularly %Clay) and W/C also have a strong influence in the stiffness prediction of laboratory mixtures with a relative importance of around 41% and 13% respectively. In other words, one can say that the laboratory mixtures stiffness prediction is a function of cement content, mixture porosity and time of cure, which is also conditioned by the clay content of the soil. Relating to soilcrete mixtures, the three most relevant variables for stiffness prediction are t, Civ and ω, with a weight higher than 50%. A particular emphasis goes to t that has a relative importance around 25%.
 Fig. 9
Fig. 9When comparing the key variables in stiffness prediction for laboratory and soilcrete mixtures, significant differences are observed. Although there are some variables that are not common to both mixtures (laboratory and field), for those that are common (e.g., W/C, n/(Civ)d or t) significant differences in the relative importance are observed. For example, while in laboratory mixtures n/(Civ)d has a relative importance of 23%, in soilcrete mixtures its influence is 9%. Concurrently, a difference around 50% is observed for W/C. Yet, in both situations either the age of the mixture or the cement content (directly through Civ or indirectly through n/(Civ)d) were identified as key variables in stiffness prediction of JG mixtures.
Measuring the average influence, Fig. 10 plots the VEC curve of t for stiffness prediction according to the SVM-E0.Lab model, displaying an exponential shape. This behaviour, where the highest influence of t is observed until 28 days time of cure, is in line with the empirical knowledge related with soil-cement mixtures. Concerning to field mixtures, Fig. 11 depicts the VEC curves of t, Civ and ω, underling the positive effect of t and Civ in the deformability properties of soilcrete mixtures. Particularly, the concave shape of t VEC curve corroborates once again the exponential influence of the time of cure in soil-cement mixtures behaviour [13,84]. On the other hand, the convex shape of Civ VEC curve indicates that, for lower cement contents, the soilcrete stiffens at a slow rate with Civ and only after a given dosage (around 0.20 → 0.40 according to the scaled x-axis of Fig. 11), does it increase at a faster rate. As expected, E0 is inversely proportional to ω, although for higher values of ω, E0 tends to increase.
 Fig. 10
Fig. 10 Fig. 11
Fig. 11Column diameter
On a JG project, column diameter (D) design is of paramount importance particularly when gaps between columns are not tolerated (e.g., groundwater control works). Thus, it is important to be able to accurately predict the column diameter in order to accomplish the project requirements. To achieve that, the same three DM algorithms applied on UCS and E0 studies (ANN, SVM and MR) were trained for JG column diameter prediction [75]. Fig. 12 illustrates the scatterplot of the SVM model (from now termed as SVM-D.Field), showing a high accuracy with all points very close to the diagonal line that represents a perfect prediction. This figure also compares the SVM-D.Field model with the ANN-D.Field and the MR-D.Field models, showing that a JG column diameter prediction cannot be handled by a linear law (MR-D.Field model). Although in Fig. 12 all points are approximately grouped around seven distinct zones, it should be noted that the proposed models predict D as a continuous value and not as discrete numbers. The metrics MAD, RMSE and R2 of SVM-D.Field are also included in this figures, underling once again its high accuracy, having achieved an .
 Fig. 12
Fig. 12For a better understanding of what was learned by the SVM-D.Field model, a detailed sensitivity analysis [11] was performed. Fig. 13 depicts the relative importance of each variable according to the SVM-D.Field model, showing that %Sand, WS, %Clay and Dgrout are four of the most relevant variables in D prediction [65]. This ranking shows that SVM-D.Field model predicts D as a function of the soil properties, where %Sand and %Clay sums 44% of the total influence. These results are in line with the observations performed by Modoni et al. [48] on their theoretical approach for D prediction, concerning to the interaction between the soil properties, especially its granulometry (granular and cohesive), and the jet energy on JG column diameter development.
 Fig. 13
Fig. 13The VEC curves of %Sand, WS and %Clay according to the SVM-D.Field model are plotted in Fig. 14. On the one hand, it is observed that the column diameter decreases when WS increases following a logarithm law. On the other hand, the VEC curves o f%Sand and %Clay indicate that the largest D are achieved in sandy soils, while those columns built in clayey soils have the smallest ones. Moreover, comparing these two VEC curves, it is noted that a decrease in the clay fraction of the soil has a stronger impact on D than an increase in the sand fraction.
 Fig. 14
Fig. 14Slope stability identification
The third case study reported in this paper addresses engineered slopes stability condition identification [2,20]. Slopes are a key element on transportation infrastructures management, namely in highways and railways. Hence, from the point of view of transportation network management, a key issue is to identify the critical slopes of the network that require budget allocation for their maintenance or repair [34,68]. Therefore, and in order to optimize the available budget, it is important to have a set of tools that help decision makers identify such critical network points and thus make the best decision on how to allocate the available budget. However, the identification of the stability level of a given slope is often a complex multivariable modelling problem that is characterized by a high dimensionality. To approach such complex task, the learning and flexible capabilities of DM algorithms were applied on slope stability identification [77], [78], from this point referred as earthwork hazard category - EHC [96], namely ANNs and SVMs, which can automatically learn from row data through complex nonlinear mappings.
To feed the algorithms, three distinct databases were compiled, covering the three types of slopes, namely rock and soil cuttings and embankments. Fig. 15 shows the distribution of EHC classes for each database. The EHC system comprises four classes (A, B, C, and D) in which A represents a good stability condition and D a bad stability condition [77]. Each database contains information collected during routine inspections and complemented with geometric, geological, and geographic data of each slope, summing more than 50 variables [[77], [78]]. All three databases were gathered by Network Rail workers and are concerned with the railway network of the United Kingdom. For each slope, a class of the EHC system was defined by the Network Rail engineers based on their experience/algorithm [96], which was assumed as a proxy for the real stability condition of the slope for the year 2015.
 Fig. 15
Fig. 15