1. Introduction
Support for climate change mitigation policies has been mounting over the past two decades, both within countries as well as internationally. The loss of forest cover accounts for between 12 and 15 percent of the annual anthropogenic emissions of greenhouse gases – the second largest source after fossil fuel combustion (Canadell et al., 2007). Forest conservation is deemed to be a cost-effective way to mitigate climate change (Nabuurs, 2007). Not only are the opportunity costs of forest conservation relatively limited, there are also substantial co-benefits in the form of improved local climate regulation, better water storage, and biodiversity conservation (Canadell et al., 2007; Stern, 2007). Economic activities affecting loss of forest cover, especially in the drylands of Africa, include – but are not limited to – agricultural expansion, overgrazing, forest fires, demand for firewood and charcoal, over-exploitation of non-wood forest products, and mining (Griscom et al., 2017). In addition, the increasing need to grow food for a growing population around the world, coupled with the still widespread use of non-sustainable production practices, translates into increasingly serious forest degradation which threatens the livelihoods of both current and future generations. Halting deforestation has thus become a central objective in the climate policy of international agencies. A key example in point is the United Nations' initiative “Reducing Emissions from Deforestation and Forest Degradation” (REDD+) (Ministry of the Environment and Sustainable Development, Government of Burkina Faso, 2012). This initiative has gained wide popularity since the 2015 Paris Agreement, and several new countries have joined (or are preparing to join) this initiative.
Effective protection of forest resources requires detailed knowledge about the status of the resources, as well as the capacity to monitor changes. More importantly, the implementation of conservation policies such as payments for avoided deforestation, or the assessment of the impacts of forest conservation programs in general, demands the ability to regularly estimate – and as accurately as possible – the size of the resource stock as well as the changes therein. Global datasets of land cover, including tree cover, are now publicly available, including Global Forest Watch at 30 m resolution (based on Hansen et al., 2013), the ESA Land Cover CCI at 300 m; the Global Land Cover dataset at 30 m from China for 2000 and 2010; and Global, Landsat-based forest-cover change from 1990 to 2000 from Kim et al. (2014); for an overview, see Tsendbazar et al. (2014). Global land cover datasets are critical and cost-effective sources of information when national mapping capacity is not available yet. But national mapping is considered more accurate, as it can better account for the local circumstances (Global Forest Observation Initiative, 2014). Definitions of both land use and forest cover can vary largely with the context.
In this paper we present a low cost, easy to implement alternative approach to estimate forest cover relying on 10-m resolution Sentinel-2 imagery, highlighting the potential of large temporal and spatial capabilities using free publicly-accessible platform and data. This method will be especially useful for those countries that lack national mapping capacity to estimate their forest inventory, including many of the more arid countries in Africa. We leverage recent advances in satellite imagery technology to analyze large sets of images, and develop a land cover map for twelve Burkina Faso gazetted forests. The paper contributes to the available literature on satellite based image classification to map forest cover, especially in the drylands of Sub-Saharan Africa (SSA). We show the use of different spectral bands and remote sensing-derived indices to run a multi-spectral-based assessment at the pixel level, which is our spatial analysis unit. In addition, we present the accuracy metrics of our estimations at three different probability thresholds indicating how true positive and true negative rates change across them.
This research is implemented as part of DIME's impact evaluation support to the Forest Investment Program (FIP) in Burkina Faso, a targeted program of the Strategic Climate Fund set up under the Climate Investment Funds (CIF)3(Climate Investment Funds, 2014), from which Burkina Faso has benefited. The project includes the Gazetted Forest Participatory Management Project for REDD+ (PGFC/REDD+) financed through the African Development Bank (AfDB) (African Development Bank Group, 2013), which is aiming to conserve forest cover in Burkina Faso. The information provided in this paper will enhance Burkina Faso's ability to plan, implement and monitor the success of their FIP, and provide lessons for other countries in the region that are also part of the FIP initiative.
In this paper, we present tree cover estimates for the 12 gazetted forests in Burkina Faso that are targeted by the FIP project, between March and April 2016. The method used relies on a multi-spectral image classification at 10-m resolution, improving the prediction power, and therefore the mapping precision, compared to Landsat-based classifications. Sentinel-2 imagery contains thirteen spectral bands, four of which are sensed at a 10-m resolution: red, green, blue and near infrared (NIR) bands (European Space Agency, 2017). Goldblatt et al. (2017) have found that higher-resolution images improve the classification accuracy of ecosystems with relatively little tree crown cover, like forests in arid or semi-arid areas, which cannot be detected with Landsat imagery.
Image classification is performed using a random forest algorithm as classifier, as well as the Google Earth Engine (GEE) platform which combines a multi-petabyte catalog of satellite imagery and geospatial datasets with planetary-scale analysis capabilities allowing faster GIS and remote sensing computing. The general classification approach is based on the construction of a ground truth dataset that leverages on a false color composite image to label pixels with higher accuracy, and then uses a k-fold cross-validation approach to determine the probability of a trained pixel to be classified as tree-covered based on its spectral signature. The output is a collection of binary rasters that covers the total area of each one of the 12 gazetted forests of interest, indicating the existence of trees and displaying the accuracy rate of the results.
This paper is organized as follows. Section 2 describes the area of study indicating the agro-ecological characteristics of the forests of interest as well as the method and data used for the classification. Section 3 cover the calculations and the data construction process while section 4 presents the classification results. The fifth section concludes the paper with a discussion of the results.
2. Materials and methods
2.1. Study context
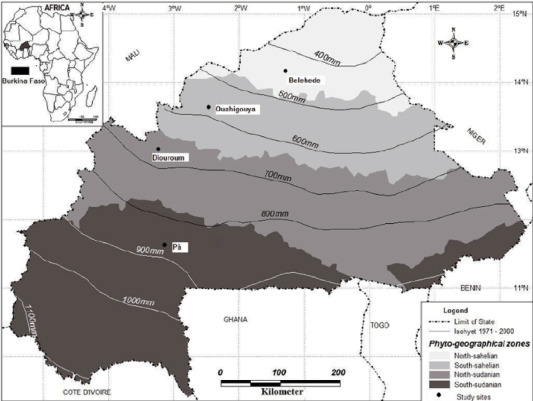
Burkina Faso is a landlocked country in West Africa, located in the drylands of Sub Saharan Africa (SSA), between the Sahara Desert and the Gulf of Guinea (Bastin et al., 2017). Most of the country belongs to the Sahel region, with semi-arid climatic conditions, considered as the transition between the Sahara and the Sudanian Savanna with vegetation dominated by shrubs and steppe (United States Geological Survey, 2016). The southern part of the country is the transition between the Sahelian and Sudanian climates characteristic of a tropical savanna. While the north receives an average rainfall of 300–400 mm per year, the south is a more humid area that receives an average annual amount of rainfall of 650–1000 mm and is irrigated by permanent rivers (United States Geological Survey, 2017). As defined by Fontès and Guinko (1995), Burkina Faso's agro-ecological zoning distinguishes four main phytogeographical zones: (from north to south) North Sahelian, South Sahelian, North Sudanian, South Sudanian (Fig. 1). While the North Sahelian is the most arid part of the country, the South Sudanian is benefited by more abundant rainfall and greener vegetation. The North Sudanian and the South Sahelian are the transition between the other two zones and show distinct climate conditions, thus the density and phenological patterns between them varies.
 Fig. 1. Agro-ecological zones in Burkina Faso. Source: Bognounou et al. (2010).
Fig. 1. Agro-ecological zones in Burkina Faso. Source: Bognounou et al. (2010).Burkina Faso is implementing a FIP-funded forest conservation program targeting 12 out of 77 gazetted forests, with the assistance of the African Development Bank (AfDB) and the World Bank Group (WBG). The forest classification analyses in this paper focus on those 12 forests, and the output offers a benchmark against which the effectiveness of forest conservation projects can be assessed in the future. Table 1 and Fig. 2 present the 12 gazetted forests targeted by the Burkina Faso FIP, where the majority of them (eight) are located in the North Sudanian and the other four in the South Sudanian.
Table 1. Forests participating in the Forest Investment Program (FIP) with their agro-ecological zones.
| Forest | Agro-ecological zones | Name |
|---|---|---|
| 1 | South Sudanian | Bontioli Gazetted Forest (Total Reserve) |
| 2 | South Sudanian | Bontioli Gazetted Forest (Partial Reserve) |
| 3 | North Sudanian | Tissé Gazetted Forest |
| 4 | North Sudanian | Sorobouli Gazetted Forest |
| 5 | South Sudanian | Sylvo-pastoral Zone of Tapoa - Boopo |
| 6 | North Sudanian | Toroba Gazetted Forest |
| 7 | South Sudanian | Nazinon Gazetted Forest |
| 8 | North Sudanian | Kari Gazetted Forest |
| 9 | North Sudanian | Tiogo Gazetted Forest |
| 10 | North Sudanian | Ouoro Gazetted Forest |
| 11 | North Sudanian | Koulbi Gazetted Forest |
| 12 | North Sudanian | Nossebou Gazetted Forest |
 Fig. 2. The locations of the gazetted forests in Burkina Faso, including the 12 FIP forests.
Fig. 2. The locations of the gazetted forests in Burkina Faso, including the 12 FIP forests.2.2. Leveraging recent advances in remote sensing technology
The recent advances in satellite imagery and processing technology have improved the availability of low to no cost satellite images, at sufficiently high temporal and spatial resolutions. This has, in turn, pushed the boundaries of forest observation capacities, allowing the development of global land cover mappings of relatively medium to high resolution to allow cost effective forest monitoring. Likewise, new cloud-based platforms such as GEE have provided capability for storing petabytes of satellite images at a global scale, and algorithms for supervised image classification, with free access for research purposes. These advances allow the collection and processing of data at a much larger scale and at higher accuracy even in relatively inaccessible areas and in regions with insufficient data collection capacity.
Until now, the most commonly used tool to (Hansen et al., 2007). This dataset relies on Landsat imagery, and is useful to estimate changes of forest cover especially in densely forested regions (Churches et al., 2014). It has been used in several studies to evaluate the impact of forest conservation policies (e.g. Blankespoor et al. (2017)). A popular application of the Hansen dataset is the Global ForestWatch, a joint effort from different organizations to make forest cover layers readily available via an easy-to-use tool (University of Maryland, 2015).
While other global-scope land cover products (i.e. (Hansen et al., 2007), (Tsendbazar et al., 2014)) are available, these products trade global coverage for local accuracy in some contexts (Mitchard et al., 2015). We build on these global approaches by leveraging similar approaches in a localized context to create a land cover m quantify forest change globally is the Hansen's dataset developed using time-series analysis of Landsat images. This dataset has been published in three versions which are updated yearly since its first publication in 2013ap for Burkina Faso, providing improved temporal and spatial resolution.
2.3. Sentinel-2 imagery
The European Sentinels consist of a fleet of satellites dedicated to providing imagery for Earth observation purposes. Sentinel-2 is part of the European Commission's Copernicus program and provides higher multispectral resolution with 13 bands that help to monitor variability in land surface conditions over large areas every 10 days (European Space Agency, 2015).
This mission supports Copernicus environmental studies that include monitoring of vegetation, soil, water and coastal areas. Amongst Sentinel-2 bands, blue (band 2), green (band 3), red (band 4), RGB, and NIR (band 8), are available at a 10 m resolution (European Space Agency, 2015). The other bands are available at 20-m or 60-m resolutions. These images are freely accessible to the public, and hence represent a low-cost solution for Earth observation and image processing at higher temporal and spatial resolution and with multispectral information.
2.4. Ground truth training dataset construction
This study uses Sentinel-2 imagery with bands of spatial resolution that range from 10 to 60 m, facilitating the detection of forest covered areas that may be imperceptible to lower resolution imagery such as Landsat. It offers an alternative for tree cover classification without the need for expensive very high-resolution images. The strategy in this paper for mapping tree cover is based on supervised classification that uses ground truth labels. Our approach was as follows.
First, we selected the images from the Sentinel-2 image library that were suitable for the creation of ground truth data. For this, we filtered images with least cloud cover in 2016 found between March and April, coinciding with Burkina Faso's dry season. Since Sentinel-2 imagery comes with 13 spectral bands, it is possible to use different color combinations to facilitate the visual detection of tree cover in the study area. Using the combination of red, green and blue color bands, the contrast between tree cover and other types of land cover is relatively low, and hence it is hard to determine the location of trees from simple visual appreciation. Instead, we used the combination of the NIR band, color red and color green to generate a color composite known as false color. The false color composite shows trees in brighter color red contrasting with darker and lighter colors of other types of land cover. However, as evidenced by Fig. 3, this composite still does not allow for accurate detection of the differences between the various types of non-tree land cover.
 Fig. 3. Sentinel-2 10-m resolution using RGB band combination vs false color combination (NIR, red and green) for a sylvo-pastoral zone in the Tapoa Boopo forest. From left to right: a) shows Google high resolution basemap as a visual reference, b) shows the Sentinel-2 RGB image and c) shows the Sentinel-2 false color image. The Sentinel-2 images were obtained in March 2016. (For interpretation of the references to color in this figure legend, the reader is referred to the Web version of this article.)
Fig. 3. Sentinel-2 10-m resolution using RGB band combination vs false color combination (NIR, red and green) for a sylvo-pastoral zone in the Tapoa Boopo forest. From left to right: a) shows Google high resolution basemap as a visual reference, b) shows the Sentinel-2 RGB image and c) shows the Sentinel-2 false color image. The Sentinel-2 images were obtained in March 2016. (For interpretation of the references to color in this figure legend, the reader is referred to the Web version of this article.)Second, we created four 100-square kilometer polygons of equilateral square shape across the 12 project forests, capturing as much as possible the variation in agro-ecological conditions (Fig. 4). Inside each square polygon, a total of 1000 ground truth points were randomly selected, and coded manually using visual interpretation, to serve as ground truth data. The 4000 ground truth points were displayed overlaying a Sentinel-2 image where each point falls into a 100-square kilometer polygon. We manually assigned a value of ‘0’ if that pixel visually did not have the characteristics of a tree pixel and a value of ‘1’ if the pixel has tree characteristics (see Fig. 5). We decided to not include other classes of land cover to remain consistent with our original goal which focuses primarily on tree cover mapping in forests areas as opposed to land cover mapping generally. In addition, we found, in our areas of interest, that the pixels that cover built-up areas and water bodies were too few to include them in the classification algorithm – not very surprising, as these are gazetted forests. While Sentinel-2 images show distinguishable patterns between different types of crops in other regions of the world (Belgiu and Csillik, 2018), in this case are not so evident. Since our assessment only considers the winter season when soil and moisture is significantly lower, crop fields that do not depend on an irrigation system (that is most of the cases in this area) reflect a very similar spectral signature to the surrounding vegetation. In addition to this, most of the gazetted forests show a lower agricultural activity, resulting in a low percentage of crop field ground truth points compared to other land cover classes.
 Fig. 4. Identification of four 100-square kilometers. polygons within the 12 project forests, taking into account the geographic distribution of the country's gazetted forests, the various agro-ecological zones they are located in as well as their latitudes, to account for differences in ecosystems across the country.
Fig. 4. Identification of four 100-square kilometers. polygons within the 12 project forests, taking into account the geographic distribution of the country's gazetted forests, the various agro-ecological zones they are located in as well as their latitudes, to account for differences in ecosystems across the country. Fig. 5. Ground truth dataset created from random points overlying Sentinel-2 images where tree covered pixels are identified with a brighter color red. (For interpretation of the references to color in this figure legend, the reader is referred to the Web version of this article.)
Fig. 5. Ground truth dataset created from random points overlying Sentinel-2 images where tree covered pixels are identified with a brighter color red. (For interpretation of the references to color in this figure legend, the reader is referred to the Web version of this article.)2.5. Classification assessment
Every Sentinel-2 image consists on 13 spectral bands the combination of which results in a spectral signature for each pixel. RGB bands create color contrasts between different types of land cover that a naked eye can distinguish and these bands represent an important part of the pixel's spectral signature. However, using only the RGB would limit the wavelength range of our classification method from 0.45 to 0.69 μm, while the full range of the wavelength reflected from the surface could reach up to 2.5 μm using the remaining bands available on these images (European Space Agency, 2015). For example, the NIR (0.7 μm–0.9 μm) band provides information about the greenness of the reflected surface which helps us to identify live and healthy vegetation, while the short-wave infrared (SWIR) (0.9–2.5 μm) bands provide information about the water content of the surface being useful to differentiate dry bare land from wet soils where vegetation is more likely to exist (Davison et al., 2006). Furthermore, their higher wavelengths are less affected by atmospheric disturbances and are used to build indices that are used to detect vegetated and non-vegetated land cover. In addition to these bands, we use three bands with 60 m spatial resolution: aerosols (band 1), water vapor (band 9) and cirrus (band 10). They provide data that is not reflected from the surface but they do provide relevant information for atmospheric corrections. While we selected images with low percentage of cloud cover during Burkina Faso's dry season, smaller clouds and airborne particles formed by evaporation, fires, pollution, etc. could be affecting the absorption of sunlight and therefore the reflectance values of the bands' wavelengths. The information from these bands is included as part of the prediction input to add data from unobserved patterns that might be affecting the other bands reflectance values. These are also rescaled to the resolution of the classification output (10 m) using the nearest neighbor method.
The Sentinel-2 image bands can be used to calculate indices that are able to capture specific types of land cover, and are especially useful for detecting (changes in) vegetation and soil (Pesaresi et al., 2016). Puletti et al. (2018) have found that including vegetation indices to the machine learning algorithmproduce better classification results compared to those obtained when it's only used the simple images, therefore we have calculated and included the following:
-
•
Normalized difference vegetation index (NDVI): reflects the relation between red visible light (RED, which is typically absorbed by a plant's chlorophyll) and NIR wavelength (which is scattered by the leaf's mesophyll structure) (Glenn et al., 2008). The NDVI is calculated as (NIR-RED)/(NIR + RED);
-
•
Normalized difference water index (NDWI): captures the amount of water present in leaf internal structures and is useful to detect water bodies (Gao, 1999). Short wave infrared (SWIR, with wavelengths between 1400 and 2400 nm) is absorbed by water, and hence can be used to detect the presence of soil in plants. The NDWI is calculated as (NIR-SWIR)/(NIR + SWIR);
-
•
Normalized difference built index (NDBI): captures the relation between the SWIR and the near infra-red wavelengths (Zha et al., 2013). Contrasting the other indices where the NIR band appears with a positive sign in the numerator, here it is subtracted showing higher values in areas with low vegetation. The index assumes a higher reflectance of built-up areas in the medium infra-red wavelength range than in the near infra-red. In forests like Bontioli, where small built-up areas can be found, the NDBI will give additional information to confirm that those pixels should not be classified as non tree cover. It is calculated as: (SWIR-NIR)/(SWIR + NIR);
-
•
Enhanced vegetation index (EVI): index that improves sensitivity in high biomass regions reducing the atmosphere influences, especially in areas of dense canopy which uses the blue band to correct aerosol influences in the red band, showing photosynthetically active vegetation (Huete et al., 1994, 1997, 2013). It is calculated as: G * ((NIR - RED)/(NIR + C1 * RED - C2 * BLUE + L)), where coefficients are adopted from the MODIS-EVI algorithm indicating the gain factor (G = 2.5), the adjustment for correcting differential, red radiant and non-linear transfer through canopy (L = 1), and the aerosol resistance term which corrects atmospheric influences in the red band (C1 = 6 and C2 = 7.5). EVI adjustments are designed to make EVI more robust than NDVI in areas with high soil exposure and in dense vegetation, but also more sensitive than NDVI to variation in the viewing geometry, surface albedo, and sun elevation angle across variable terrain (Garroutte et al., 2016). However, there are some existing scientific controversies that question the use of EVI (Morton et al., 2014; Saleska et al., 2007), therefore we decided to also include NDVI, an index that has been widely used in remote sensing and classification algorithms, for example: Puletti et al. Puletti et al. (2018); Goldblatt et al. (2016, 2017). The inclusion of these two indices that are highly correlated, does not affect the model's prediction power and results, since Random Forest classifier is a nonlinear algorithm (Breiman, 2001) and these are less affected by multicollinearity (Morlini, 2006; Feng et al., 2018);
-
•
Urban index (UI): measures the density of man-made constructions where higher values indicate a higher built-up intensity area (Kawamura et al., 1996). It is calculated as: (SWIR2 - NIR)/(SWIR2 + NIR). The SWIR2 band corresponds to the short-wave infrared with a wavelength between 2107 nm and 2294 nm that represent the highest wavelength values of Sentinel-2 bands which are reflected when some minerals like metals appear. Therefore, when SWIR2 values are higher relative to NIR values, this typically means that the pixel lacks vegetation and contains more built-up areas, similar to how the NDBI works. The inclusion of the NIR is helpful to identify areas with no vegetation as the NDBI does, but with the SWIR2 band, reflectance with higher bandwidths will be captured. Using this index, a larger bandwidth spectrum is covered, adding information to detect possible patterns of more types of land cover that should not be classified as tree cover.
While RGB and NIR are sensed at a 10 m resolution, the short wave infrared bands (SWIR1 and SWIR2) are available at a 20 m resolution. To address this spatial resolution difference, the pixel values with lower resolution are re-sampled to fit the 10 m resolution using the nearest neighbor method. The classification assessment consisted in dividing the ground truth data randomly into five folds to perform a k-fold cross validation that could use four folds to train the pixels and one fold to test the accuracy of the results (Fisher et al., 2017). That means that each set of ground truth points for each fold inside a sample polygon was used four times as a training point and one time as a test point.
Because the methodology relies on a supervised classification method, we needed to find an adequate classifier to train and classify pixels. A classifier is a collection of condition-action rules used in learning systems (Lanzi et al., 2018). Classifiers can be found in two types: parametric and non-parametric. A parametric classifier is based on the statistical probability distribution of each class and relies on the statistical data of samples. A non-parametric classifier is used to estimate the probability of unknown density functions, such as those used in machine learning (Kumar and Sahoo, 2012). There are a number of classification algorithms that we could use for our classification. Since the purpose of this work is not to test the differences between different classifiers, we rely on previous studies that have used different classification algorithms to run similar experiments. Goldblatt et al. (2016) tested three different classifiers to classify land cover: (i) the Classification and Regression Tree classifier (CART); (ii) the Support Vector Machine classifier (SVM); and (iii) the Random Forest classifier. Belgiu and Dragut (2016) have tested the Random Forest classifier in remote sensing and found that it successfully handles high data dimensionality and multicolinearity, being both fast and insensitive to overfitting (Belgiu and Dragut, 2016). Goldblatt et al. (2017) have also used Random Forest to classify tree cover in Brazilian semiarid ecosystems with similar results and Puletti et al. Puletti et al. (2018) have reached an accuracy rate of 83% when using Random Forest to map types of forest cover in the Italian Mediterranean. A Random Forest classifier is a supervised learning method that uses kernel functions (vectors within matrices) to define vector parameters of the data producing multiple decision trees, using a randomly selected subset of training samples and variables (Belgiu and Dragut, 2016). In practice, the method consists of a decision-tree classifier that includes k-decision trees (k-predictors) (Cutler et al., 2012; Karlson et al., 2015) When classifying an example, the example variables are run through each of the k tree predictors, and the k predictions are averaged to get a less noisy prediction (by voting on the most popular class). The learning process of the forest involves some level of randomness; each tree is trained over an independent random sample of examples from the training set and each node's binary outcome in a tree is determined by a randomly sampled subset of the input variables (Rodriguez-Galiano et al., 2012).
3. Calculations
The overall method flowchart used in this paper is summarized in Fig. 6. Our ground truth dataset consists of 4000 ground truth points. Using this ground truth data and the classifier described above, we trained all pixels within each of the 12 FIP forests. The pixel-based classification method used the thirteen spectral bands of Sentinel-2 imagery plus the five indices explained above. The number of trees used for Random Forest classifier was determined based on Goldblatt et al. (2016, 2017). Goldblatt et al. estimated the average accuracy that resulted from using 1, 3, 5, 10, 50 and 100 decision trees. They found that on average, accuracy was highest when using between 10 and 50 decision trees. Based on this evidence, we also decided to use 20 decision trees for our assessment.
